Auditen van de eerlijkheid van een algoritme, met behulp van statistiek
Eind 2024 trad de EU-wetgeving op kunstmatige intelligentie (AI) in werking. Deze wetgeving is opgesteld om het toenemende gebruik van AI in besluitvormings- en beslissingsondersteunende systemen te reguleren. Volgens de Europese AI-Act moeten AI-systemen met een hoog risico, zoals algoritmes die cv's screenen of kredietscores voorspellen, worden gecontroleerd om te waarborgen dat ze eerlijk zijn en geen discriminatie veroorzaken. Hoewel de primaire verantwoordelijkheid voor deze audits bij de AI-leverancier ligt, zijn er situaties waarin een externe, onafhankelijke auditor de controle moet uitvoeren.
Federica Picogna en Koen Derks
Algoritmen kunnen de efficiëntie verhogen, maar ook leiden tot discriminatie van bepaalde groepen mensen. Zo kan een bank bijvoorbeeld een algoritme inzetten om kredietaanvragen te beoordelen en te bepalen of een aanvrager in aanmerking komt. Dit verhoogt de efficiëntie, doordat het algoritme snel grote hoeveelheden aanvragen verwerkt en vaststelt wie in aanmerking komt. Medewerkers kunnen vervolgens de aanbevelingen van het algoritme gebruiken om hun besluitvorming te versnellen. Als het algoritme echter is getraind op historische gegevens die bestaande vooroordelen weerspiegelen, kan het bijvoorbeeld onevenredig vaak adviseren dat aanvragers met een migratieachtergrond worden afgewezen. Dit is oneerlijk en leidt tot discriminatie. De bankensector (De Nederlandsche Bank, 2025), planbureaus (Centraal Planbureau, 2023), en ngo's (Algorithm Audit, 2025) zijn zich overigens bewust dat het gebruik van algoritmes kan leiden tot ongewenste discriminatie en doen daarom ook onderzoek naar manieren om dit te herkennen en voorkomen.

Het controleren van algoritmen op eerlijkheid is uitdagend, omdat het vakgebied nog relatief nieuw is. Daardoor ontbreekt het veel auditors aan de nodige ervaring of expertise. Daarnaast zijn er maar weinig gebruiksvriendelijke softwareprogramma's beschikbaar die auditors hierbij kunnen ondersteunen. In deze column laten we zien hoe je de gratis en open-source software JASP (JASP Team, 2025) kunt gebruiken om de eerlijkheid van een algoritme te evalueren, zelfs met minimale statistische kennis. JASP vereenvoudigt dit proces en genereert automatisch een auditrapport waarin de analyse en resultaten overzichtelijk worden vastgelegd.
Eerlijkheidsmaten
Voordat we een praktisch voorbeeld bespreken, lichten we kort het concept van algoritmische eerlijkheid toe aan de hand van een voorbeeld van een zogenoemde eerlijkheidsmaat. Een eerlijkheidsmaat is een manier om te kwantificeren of een algoritme bepaalde groepen mensen gelijk behandelt, of juist bepaalde groepen mensen benadeelt, zelfs wanneer het gevoelige kenmerk over groepsidentiteit zelf niet als invoer voor het algoritme wordt gebruikt. Hoewel een algoritme vaak juist bedoeld is om te selecteren en dus te onderscheiden, oftewel te discrimineren, is het niet de bedoeling dat dit gebeurt op basis van kenmerken die verband houden met bijvoorbeeld etniciteit, religie of vergelijkbare factoren.
Om bijvoorbeeld te bepalen of het eerdergenoemde algoritme voor het screenen van kredietaanvragen discrimineert tegen aanvragers met een migratieachtergrond, kun je nagaan of het algoritme in aanmerking komende aanvragers aanbeveelt, ongeacht hun demografische achtergrond. Soms beveelt het algoritme namelijk aan om zulke aanvragers toch af te wijzen. Eén manier (van de vele1) om eerlijkheid te evalueren, is door te kijken naar de proportie van onterecht aanbevolen afwijzingen - de zogenoemde fout-negatieven - voor elk type demografische achtergrond. Dit wordt de proportie fout-negatieven genoemd.
De intuïtie achter algoritmische eerlijkheid is dat, wanneer de proporties fout-negatieven vergelijkbaar zijn voor alle demografische achtergronden, het algoritme niet onevenredig vaak aanbeveelt om in aanmerking komende aanvragers met een bepaalde achtergrond af te wijzen. Zijn deze proporties echter substantieel verschillend, dan wijst dat erop dat het algoritme aanvragers met een bepaalde achtergrond vaker onterecht afwijst dan andere. Als ook overeenkomstig de aanbevelingen van het algoritme wordt gehandeld, leidt dit tot discriminatie.
Algoritmische eerlijkheid wordt vaak gekwantificeerd met behulp van zogenoemde pariteitsmaten. Een voorbeeld hiervan is de verhouding tussen twee proporties fout-negatieven, ook wel de fout-negatieve proportie pariteit genoemd. Wanneer deze verhouding dicht bij één ligt, betekent dit dat de proporties fout-negatieven voor beide groepen vergelijkbaar zijn. In dat geval wordt het algoritme als eerlijk beschouwd met betrekking tot deze maat en leidt het niet tot discriminatie. Merk op dat het voor de meeste eerlijkheidsmaten essentieel is om over een vorm van 'de waarheid' te beschikken voor een paar gevallen, bijvoorbeeld door een expert te laten vaststellen wat het juiste antwoord is dat het algoritme probeert te voorspellen.
Casus ter illustratie: kredietaanvragen beoordelen met een algoritme
Laten we dit voorbeeld concreter maken met gegevens. Stel dat je als externe auditor de taak hebt om de eerlijkheid van het eerdergenoemde algoritme voor het screenen van kredietaanvragen te beoordelen. Je beschikt over gegevens van tweehonderd aanvragers uit het systeem van de bank, waaronder hun demografische achtergrond (geen migratieachtergrond, tweede generatie migratieachtergrond of eerste generatie migratieachtergrond) en de aanbevelingen van het algoritme. Daarnaast heeft een juridisch expert van jouw kantoor onafhankelijk beoordeeld of deze aanvragers in aanmerking komen voor krediet, zonder kennis van hun demografische achtergrond. Deze gegevens zijn samengevat in de onderstaande tabel.
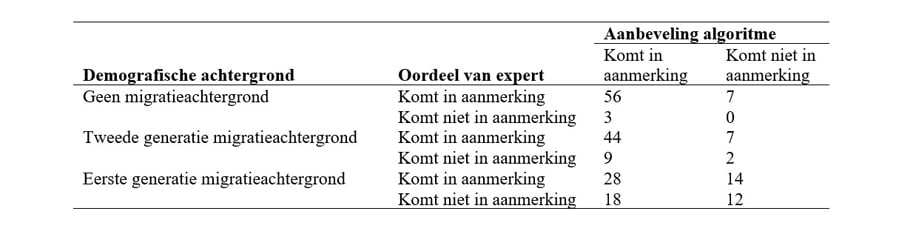
Om te bepalen of dit algoritme eerlijke aanbevelingen geeft, bepaal je eerst een eerlijkheidsmaat en toets je vervolgens statistisch de nulhypothese dat de eerlijkheidsmaat voor alle demografische achtergronden hetzelfde is.
Berekenen van een eerlijkheidsmaat
Aanvragers die zowel door het algoritme als door de expert als in aanmerking komend worden beoordeeld, worden echt-positieven (true positives, TP) genoemd. Daarentegen worden aanvragers die door het algoritme worden afgewezen, maar volgens de expert wél in aanmerking komen, fout-negatieven (false negatives, FN) genoemd2.
Voor elke demografische achtergrond kun je de proportie fout-negatieven berekenen door het aantal fout-negatieven te delen door het totale aantal aanvragers die volgens de expert in aanmerking komen (TP + FN). Eén manier om de fout-negatieve proportie pariteit (false negative rate parity, FNRP) te bepalen, is om vervolgens de verhouding tussen de proportie fout-negatieven van aanvragers met een migratieachtergrond (de niet-bevoorrechte groepen) en die zonder migratieachtergrond (de bevoorrechte groep) te berekenen3.

De proportie foutnegatieven bedraagt 0,111 voor aanvragers zonder migratieachtergrond, 0,137 voor aanvragers met een tweede generatie migratieachtergrond en 0,333 voor aanvragers met een eerste generatie migratieachtergrond. Vergeleken met de groep zonder migratieachtergrond is de proportie fout-negatieven dus 1,235 keer zo hoog voor aanvragers met een tweede generatie migratieachtergrond en zelfs drie keer zo hoog voor aanvragers met een eerste generatie migratieachtergrond.
Om te beoordelen of de verschillen in fout-negatieve proporties tussen de drie demografische groepen groot genoeg zijn om te concluderen dat het algoritme oneerlijk is, kun je een statistische toets uitvoeren. In dit voorbeeld gebruik je voor deze toets een betrouwbaarheidsniveau van 95 procent (α = 0,05).
Algoritmische eerlijkheid toetsen met de hand
Om te toetsen of de fout-negatieve proporties gelijk zijn voor alle demografische achtergronden, kun je gebruikmaken van de chi-kwadraattoets. Deze toets beoordeelt of het aantal echt-positieven en fout-negatieven per groep afwijkt van wat je zou verwachten, als de aanbevelingen van het algoritme onafhankelijk zijn van demografische achtergrond voor alle groepen samen. De verwachte aantallen worden berekend door het rijtotaal te vermenigvuldigen met het kolomtotaal en dit te delen door het totaal van alle waarnemingen in de onderstaande tabel.
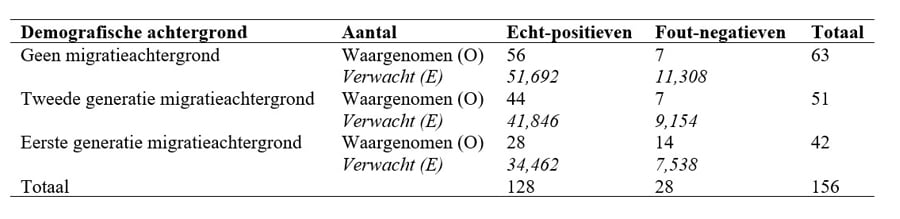
De chi-kwadraat statistiek bedraagt X2 = Σ(Oi – Ei)2 / Ei = 9,368. De bijbehorende significantie (of p-waarde) bij 2 vrijheidsgraden is 0,009 (voor details over deze berekening, zie Touw en Hoogduin, 2012, hoofdstuk 11). Omdat de significantie lager is dan het gekozen betrouwbaarheidsniveau van α = 0,05, kun je de nulhypothese van gelijke proporties fout-negatieven voor alle groepen verwerpen en concluderen dat het algoritme aanvragers met een bepaalde migratieachtergrond onevenredig vaak afwijst. Het is echter belangrijk om te benadrukken dat deze toets alleen aantoont dát er een verschil is tussen de drie groepen en niet wélke specifieke groep oneerlijk wordt behandeld.
Het opstellen van de bovenstaande tabel en het uitvoeren van de bijbehorende berekeningen kan tijdrovend en complex zijn, vooral wanneer er meer dan drie groepen zijn of wanneer je met grote datasets werkt. JASP neemt je dit werk uit handen: het voert de analyse automatisch uit, identificeert welke groep mogelijk oneerlijk wordt behandeld en genereert een auditrapport met de resultaten en een duidelijke toelichting.
Algoritmische eerlijkheid toetsen met JASP
Om de eerlijkheid van dit algoritme te toetsen met JASP, download en installeer je eerst JASP van www.jasp-stats.org. Stel de interface en resultaten in op het Nederlands via het menu in de linkerbovenhoek (Preferences - Interface - Preferred language). Laad vervolgens het gegevensbestand4 in JASP en schakel de Auditmodule in door op het '+'-symbool in de rechterbovenhoek te klikken en 'Audit' te selecteren. De module verschijnt dan in het menu bovenaan het scherm.
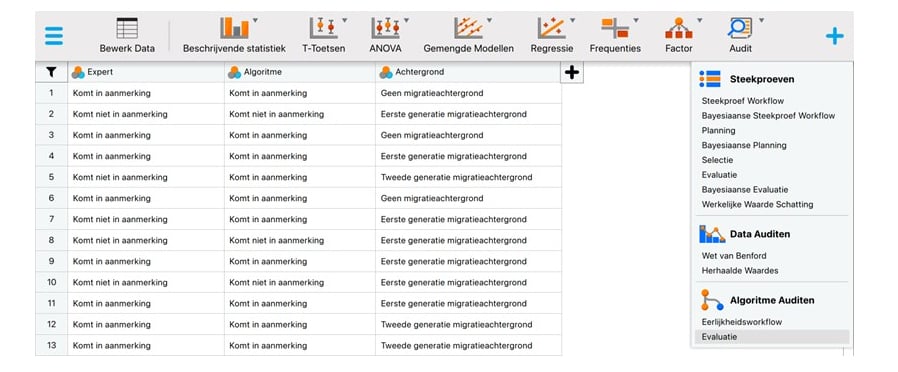
Klik eerst op de Auditmodule en selecteer de analyse 'Evaluatie' in de sectie 'Algoritme Auditen'. Sleep in de interface de variabele Expert naar het vak 'Werkelijkheid', de variabele Algoritme naar het vak 'Voorspellingen' en de variabele Achtergrond naar het vak 'Gevoelig Kenmerk'. Selecteer vervolgens 'Fout-negatieve proportie pariteit' als de 'Eerlijkheidsmaat'. Selecteer bij de opties 'Niveaus' Geen migratieachtergrond als de bevoorrechte groep en Komt in aanmerking als positieve klasse. Klik ten slotte op 'Individuele vergelijkingen' in het gedeelte 'Rapport' om een tabel op te vragen waarin de drie groepen worden vergeleken.
Resultaten
Zodra de bovenstaande opties zijn opgegeven, berekent JASP automatisch de resultaten. De onderstaande tabel geeft het aantal aanvragers (n = 200), de chi-kwadraat statistiek (X2 = 9,368), het aantal vrijheidsgraden (df = 2) en de significantie (p = 0,009) weer. Zoals eerder gezegd: omdat de significantie lager is dan α = 0,05, kun je de hypothese van gelijke proporties fout-negatieven voor alle drie de groepen verwerpen.

De tweede tabel toetst vervolgens of voor de niet-bevoorrechte groepen de proportie fout-negatieven significant verschilt van die van de bevoorrechte groep. De eerste drie kolommen tonen de proportie fout-negatieven per demografische achtergrond, samen met de bijbehorende 95 procent betrouwbaarheidsintervallen. De vierde tot en met zesde kolom laten zien hoe de proportie fout-negatieven per type migratieachtergrond zich verhoudt tot die van de groep zonder migratieachtergrond, inclusief de bijbehorende betrouwbaarheidsintervallen. Om vast te stellen welke groep oneerlijk wordt behandeld door het algoritme, kun je je richten op de laatste kolom, die de significantie aangeeft.

Alleen de groep met een eerste generatie migratieachtergrond heeft een significantie lager dan α = 0,05. Dit suggereert dat het algoritme disproportioneel aanbeveelt om in aanmerking komende aanvragers met deze demografische achtergrond af te wijzen ten opzichte van aanvragers zonder migratieachtergrond. Voor aanvragers met een tweede generatie migratieachtergrond is het verschil niet significant, wat betekent dat zij niet aantoonbaar anders worden behandeld dan aanvragers zonder migratieachtergrond. De conclusie uit de tweede tabel is genuanceerder dan die van de chi-kwadraattoets uit de eerste tabel, omdat deze niet alleen laat zien dát er een significant verschil in behandeling is, maar ook wélke groep significant anders wordt behandeld.
Door op de knop 'Download Rapport' te klikken, kun je de resultaten en de bijbehorende uitleg exporteren naar een HTML- of pdf-bestand. Op deze manier genereer je automatisch een auditrapport dat je analyse en bevindingen vastlegt in begrijpelijke taal, geschikt voor zowel auditors als statistici.
Merk op dat deze column slechts dient als een introductie tot het onderwerp van het toetsen van eerlijkheid. Verschillende factoren kunnen de resultaten beïnvloeden, zoals de hoeveelheid data en de vraag of men volledige eerlijkheid toetst of een zekere mate van oneerlijkheid toelaat, vergelijkbaar met hoe materialiteit in financiële audits een toegestane afwijking weergeeft. Een diepgaandere bespreking hiervan valt echter buiten de scope van dit artikel. Voor wie meer wil weten, raden we aan om onze website statisticalauditing.com in de gaten te houden voor de nieuwste methodologische ontwikkelingen in dit veld.
Conclusie
Als externe auditor kun je, na het toetsen van de eerlijkheid van het algoritme met behulp van een eerlijkheidsmaat, deze inzichten gebruiken om te rapporteren over ongelijkheden in de prestaties van het algoritme. Deze informatie is van groot belang voor de bank, zodat deze gerichte aanpassingen kan doorvoeren, zoals het bijstellen van beslissingsdrempels of het implementeren van eerlijkheidsbeperkingen, om te voldoen aan de eisen van de AI-Act. Het is echter belangrijk om te benadrukken dat deze analyse ook waardevol is voor interne IT-auditors bij AI-leveranciers, die in de praktijk vaak verantwoordelijk zijn voor het uitvoeren van dergelijke algoritme-audits.
Noten
-
Er zijn veel verschillende eerlijkheidsmaten, die elk geschikt zijn voor verschillende situaties en die elk op een andere manier eerlijkheid definiëren. Dit kan het een uitdaging maken om de meest geschikte eerlijkheidsmaat te kiezen. Om te helpen bij het kiezen van een eerlijkheidsmaat, hebben Picogna, de Swart, Kaya en Wetzels (2025) een beslisboom geïntroduceerd, die is geïmplementeerd in de 'Eerlijkheidsworkflow'- analyse in JASP for Audit.
-
De aanvragers waarvan het algoritme voorspelde dat ze niet in aanmerking kwamen en die ook door de expert als niet in aanmerking komend werden beoordeeld, worden echt-negatieven (true positives, TN) genoemd. Aan de andere kant worden de aanvragers waarvan het algoritme voorspelt dat ze in aanmerking komen, maar de expert niet, fout-positieven (false positives, FP) genoemd. Deze zijn niet relevant voor het huidige voorbeeld.
-
Een andere manier om de fout-negatieve proportie pariteit te bepalen is om te kijken naar het verschil tussen de proportie fout-negatieven van aanvragers met een migratieachtergrond en die zonder migratieachtergrond.
-
Het gegevensbestand is hier te vinden.
Referenties
-
Algorithm Audit. (2025). Empirical Methods for supervising algorithmic profiling systems. Opgehaald op 5 november 2025.
-
Centraal Planbureau. (2023). Greep op selectie-algoritmes. Opgehaald op 5 november 2025.
-
De Nederlandsche Bank. (2025). Vervolgonderzoek aanpak discriminatie banken. Opgehaald op 5 november 2025.
-
JASP Team. (2025). JASP (Versie 0.95.4) [Computer software].
-
Picogna, F., de Swart, J., Kaya, H., & Wetzels, R. (2025). How to choose a fairness measure: A decision-making workflow for auditors. OSF Preprints.
-
Touw, P. & Hoogduin, L. (2012). Statistiek voor Audit en Controlling. Boom, Amsterdam.
Gerelateerd

Voorraadcontroles: schatten van de werkelijke waarde met open-source software
Bij de controle van handels en productieondernemingen wordt vaak een fysieke voorraadcontrole uitgevoerd. Daarbij komen regelmatig afwijkingen aan het licht, bijvoorbeeld...

De Wet van Benford
De Wet van Benford kent toepassingen binnen de audit en is opgenomen in veel auditsoftwarepakketten. Een verkenning van mogelijkheden, beperkingen en toetsing met...

Symposium over statistiek in ESG
Hoe ver is de auditpraktijk met het toepassen van data-analyse op het gebied van ESG? De Stuurgroep Statistical Auditing van het Limperg Instituut gaat daarop in,...

Machine learning in de audit: stratificeren van bedrijfslocaties
In dit derde en laatste deel van een reeks columns over machine learning in de audit gaat het over clusteren. De auteurs laten zien hoe je met een open-source statistiekprogramma...

Machine learning in de audit: uitschieters bij vastgoedwaardering
Regressie is een vorm van machine learning met als doel het voorspellen van cijfers op basis van een aantal kenmerken. Met open-sourcesoftware kun je zonder programmeerkennis...