Machine learning in de audit: uitschieters bij vastgoedwaardering
Regressie is een vorm van machine learning met als doel het voorspellen van cijfers op basis van een aantal kenmerken. Met open-sourcesoftware kun je zonder programmeerkennis regressie toepassen in de audit, bijvoorbeeld om uitschieters bij vastgoedwaardering te detecteren. Deel twee van een reeks bijdragen over machine learning in de audit.
Koen Derks
Het doel van machine learning is om voorspellingen te maken aan de hand van data. Binnen dit veld worden doorgaans drie hoofdtoepassingen onderscheiden: classificatie, regressie en clusteren. In de eerste column is classificatie behandeld. Deze column gaat over regressie.
Regressie is een vorm van machine learning, waarmee je een numerieke uitkomst kunt voorspellen op basis van een aantal kenmerken. Dit kun je in een audit bijvoorbeeld gebruiken om de dagelijkse omzet van een winkel te voorspellen op basis van het aantal klanten en de locatie van de winkel, of om de loonkosten te voorspellen op basis van het aantal werknemers en de gewerkte uren. Zo kun je een inschatting maken of de gerapporteerde geldbedragen overeenkomen met realistische verwachtingen.
Tijdens de opleiding tot accountant leer je over lineaire regressie, maar machine learning biedt de mogelijkheid ook meer complexe verbanden te modelleren. In deze column gebruik ik het zogenoemde boosting algoritme als voorbeeld, hoewel er tal van andere algoritmes beschikbaar zijn.
'Het uiteindelijke doel van deze columnreeks is om je uit te dagen deze technieken zelf te gebruiken voor je eigen doeleinden.'
Het is belangrijk om te benadrukken dat het gebruik van machine learning-technieken niet zozeer een einddoel op zich is. Het biedt je de flexibiliteit om niet beperkt te zijn tot één techniek en om de resultaten van verschillende technieken, zoals boosting en lineaire regressie, te vergelijken. Op deze manier kun je de techniek selecteren die het best presteert in een afweging tussen kwaliteit en uitlegbaarheid.
In deze column laat ik zien hoe je met het gratis open-source statistiekprogramma JASP (JASP Team, 2024) zonder enige programmeerkennis een machine learning-algoritme voor regressie kunt trainen en daarna kunt toepassen in de context van een audit. Ik illustreer dit aan de hand van een voorbeeld waarbij je als auditor de uitschieters in de verkoopprijzen van woningen in de portefeuille van een vastgoedontwikkelaar wil identificeren voor een fraudeonderzoek. Let wel, dit is slechts een voorbeeld. Het uiteindelijke doel van deze columnreeks is om je uit te dagen deze technieken zelf te gebruiken voor je eigen doeleinden.
Vastgoedwaardering
Soms kunnen vastgoedontwikkelaars transacties aangaan met gerelateerde partijen tegen niet-marktconforme prijzen, om de winst te verhogen of verliezen te minimaliseren. Als de gerapporteerde verkoopprijzen aanzienlijk hoger of lager zijn dan de marktwaarde, kan dit een indicatie zijn van fraude.
'Als een woning voor een veel te lage of te hoge prijs is gewaardeerd door de vastgoedontwikkelaar, kan dit een indicatie zijn van fraude.'
Een voorbeeld hiervan is de overwaardering van objecten om leningen te verkrijgen op basis van valse waarde. Als auditor kun je in de portfolio deze verdachte objecten detecteren als outliers, oftewel uitschieters, door tijdens de audit de verwachte verkoopprijzen van de woningen te voorspellen met behulp van een regressieanalyse. Het idee is dat je uit openbare gegevens leert wat een realistische verkoopprijs is voor een woning met bepaalde kenmerken, en vervolgens controleert of de woningen in de portfolio van de vastgoedontwikkelaar daaraan voldoen.
In dit voorbeeld gebruik ik een voor deze column licht bewerkte versie van de algemeen toegankelijke Housing Prices-dataset1. Net als in de eerste column is het belangrijk om te benadrukken dat dit voorbeeldgegevens zijn. In de praktijk is het raadzaam om betrouwbare informatie uit een publieke databank te gebruiken die representatief is voor de markt waarin de vastgoedontwikkelaar actief is.
De beschikbare gegevens bevatten, naast de verkoopprijs, een aantal bouwtechnische kenmerken voor 445 woningen, zoals het aantal bewoonbare vierkante meters, het aantal verdiepingen en het aantal badkamers2. Dezelfde kenmerken zijn ook beschikbaar voor de honderd woningen in de portfolio van de vastgoedontwikkelaar3. Je wil voor de portfolio de prijzen bepalen waartegen de vastgoedontwikkelaar de woningen realistisch gezien kan verkopen. Als een woning voor een veel te lage of te hoge prijs is gewaardeerd door de vastgoedontwikkelaar, kan dit een indicatie zijn van fraude.
Training- en testset
Het uitgangspunt van een regressiealgoritme is dat er een verband bestaat tussen de bouwtechnische kenmerken van een woning en de verkoopprijs. Als je dit verband kent, kun je op basis van de kenmerken een voorspelling doen over de prijs waartegen een woning zou moeten worden verkocht. Het is echter onbekend hoe de kenmerken zich verhouden tot de verkoopprijs, dus het algoritme moet dit verband leren uit de beschikbare gegevens.
Om het verband tussen de verkoopprijs en de bouwtechnische kenmerken te leren, kun je het regressiealgoritme een deel van de beschikbare gegevens laten zien, bijvoorbeeld van 345 willekeurig geselecteerde woningen. Dit deel van de gegevens, wat zowel de bouwtechnische kenmerken als de verkoopprijs bevat, wordt de trainingsset genoemd.
Om vervolgens te evalueren of het geleerde verband goed generaliseert naar woningen die het algoritme nog niet heeft gezien, kun je een zogenaamde testset apart houden tijdens de trainingsfase. Die testset bestaat uit de resterende honderd woningen in de gegevens. Zodra deze trainings- en testset zijn vastgesteld, kun je beginnen met het trainen van een regressiealgoritme.
Trainen regressiealgoritme
Na het downloaden en installeren van JASP kun je de gegevens importeren. Vervolgens kun je de Machine Learning-module inschakelen door op het '+'-symbool in de rechterbovenhoek te klikken en 'Machine Learning' te kiezen. Hierdoor verschijnt de module in het menu boven in het scherm. Door vervolgens op de module te klikken, kun je alle functionaliteit zien die de module aanbiedt. Via het menu in de linkerbovenhoek (Preferences - Interface - Preferred language) kun je daarnaast instellen dat de interface en de resultaten in het Nederlands worden weergegeven.
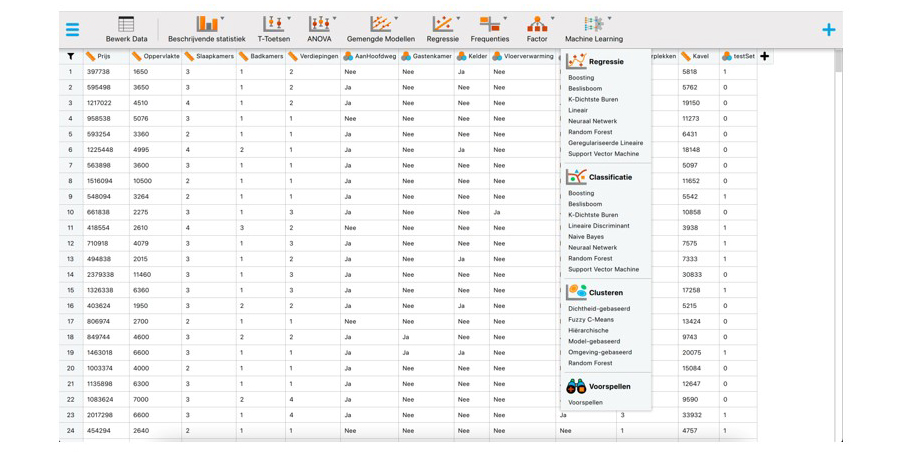
Zoals te zien is in bovenstaande screenshot, zijn er voor het leren van het verband tussen de verkoopprijs en de bouwtechnische kenmerken verschillende regressiealgoritmes beschikbaar. In deze column kies ik voor het boosting algoritme (James et al., 2023, pagina's 347-350).
Dit is een techniek waarbij opeenvolgend een aantal beslisbomen wordt getraind. Elke nieuwe beslisboom richt zich bij deze methode op de fouten die in de vorige beslisbomen zijn gemaakt. Hierdoor verbetert de voorspellende kracht van het model in elke stap. Om dit algoritme in JASP te gebruiken, selecteer je in het Machine Learning-menu de optie 'Boosting' onder 'Regressie'.
'Elke nieuwe beslisboom richt zich bij deze methode op de fouten die in de vorige beslisbomen zijn gemaakt.'
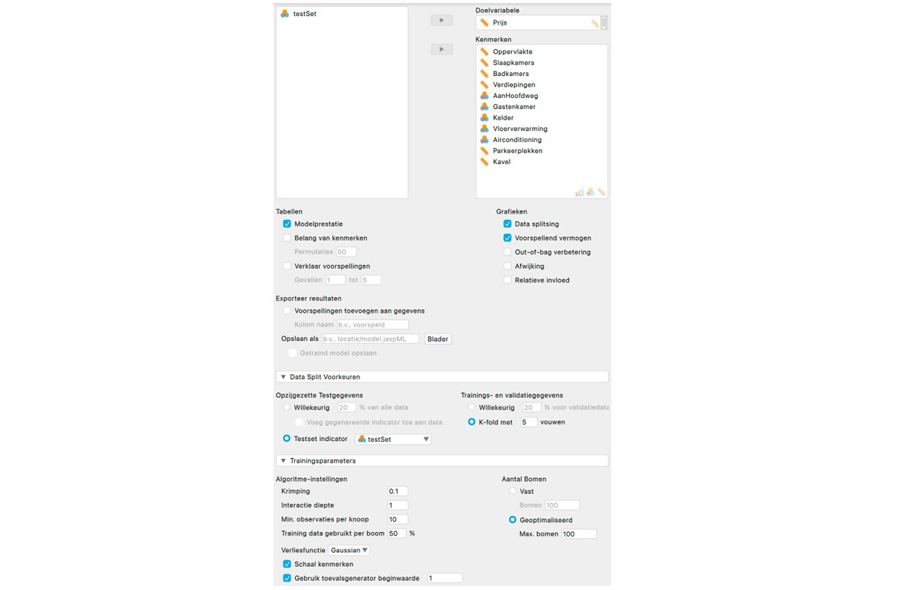
Vervolgens open je in de hieronder weergegeven interface de sectie 'Data Split Voorkeuren', selecteer je de optie 'Testset indicator' en wijs je deze de variabele testSet toe met behulp van het keuzemenu. Dit zorgt ervoor dat het algoritme de vooraf willekeurig geselecteerde 345 woningen gebruikt om het algoritme te trainen en de resterende honderd woningen gebruikt om het algoritme te evalueren.
In dezelfde sectie klik je onder 'Trainings- en validatiegegevens' op 'K-fold' (James et al., 2023, pagina's 206-208). Hiermee geef je aan dat er tijdens de trainingsfase elke keer één vijfde deel van de trainingsset wordt gebruikt als validatieset, terwijl het algoritme wordt getraind op het resterende deel van de trainingsset4. Dit proces herhaalt zich voor elk van de vijf delen van de trainingsset, met als doel het bepalen van het optimale aantal opeenvolgende beslisbomen.
Overigens hoef je de trainingsset niet noodzakelijkerwijs op te splitsen in vijf delen. In de interface kun je zelf instellen hoeveel delen er worden gebruikt. Hierbij geldt dat het opsplitsen van de trainingsset in meer delen nauwkeurigere resultaten geeft, maar meer tijd kost, terwijl het opsplitsen in minder delen sneller is, maar mogelijk minder betrouwbaar.
Na het instellen van de datasplit-voorkeuren open je de sectie 'Trainingsparameters' en vink je de optie 'Gebruik toevalsgenerator beginwaarde' aan. Hiermee initialiseer je de willekeurige getallengenerator in het boosting algoritme met de waarde 1, zodat je de resultaten uit deze column op je eigen computer kunt reproduceren. Vervolgens sleep je de variabele Prijs naar het vak voor de doelvariabele. Als laatste selecteer je alle overige variabelen behalve testSet en sleep je deze naar het vak voor de kenmerken.
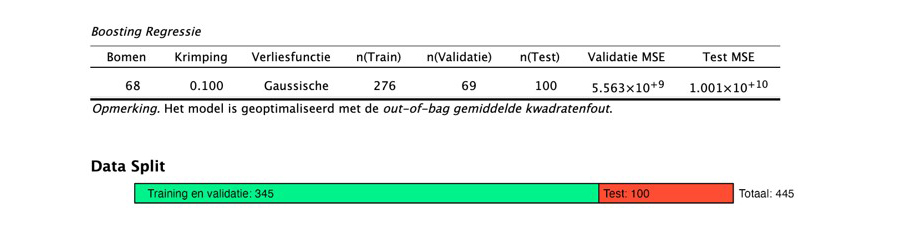
Zodra alle gegevens zijn ingevoerd, begint JASP met het trainen van het regressiealgoritme. De resulterende output is hieronder weergegeven. Uit de tabel blijkt dat het trainen en optimaliseren van het algoritme leidt tot een model dat gebruik maakt van 68 beslisbomen. In dit geval zijn er van de 345 woningen in de trainingsset vijf keer 276 woningen (345 × 4/5) gebruikt om het model te trainen, en zijn er vijf keer 69 woningen (345 × 1/5) gebruikt om het model te optimaliseren/valideren. Verder toont de output dat dit model een gemiddelde kwadratenfout (MSE, Mean Squared Error) van 1,001 1010 behaalt op de honderd woningen in de testset.
Kwaliteit evalueren
De gemiddelde kwadratenfout wordt gebruikt om een regressiemodel te optimaliseren en is de standaardmaat voor het evalueren van de kwaliteit ervan. Optimaliseren in deze context betekent het aantal bomen zoeken, wat resulteert in de laagste gemiddelde kwadratenfout.
De interpretatie van deze kwaliteitsmaat is echter relatief complex. Voor een meer intuïtieve evaluatie van het model, kun je bovenaan de interface onder het kopje 'Tabellen' de optie 'Modelprestatie' aanvinken. Hierdoor krijg je de onderstaande tabel te zien met een aantal kwaliteitsmaten. Deze kwaliteitsmaten kwantificeren op verschillende manieren hoe goed de voorspellingen van het algoritme overeenkomen met de werkelijke verkoopprijzen in de testset.
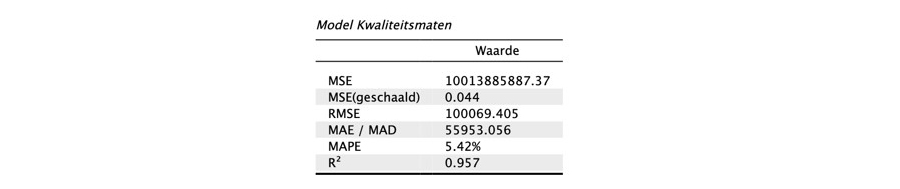
De bovenste rij van de tabel bevat de eerdergenoemde gemiddelde kwadratenfout5. Deze geeft aan dat het gemiddelde verschil tussen een voorspelde en een werkelijke verkoopprijs in de testset, wanneer gekwadrateerd, 10.013.885.887,37 is. Het is belangrijk om op te merken dat het hier om het gemiddelde gekwadrateerde verschil gaat en niet om het gemiddelde daadwerkelijke verschil. De reden hiervoor is dat de voorspellingen van het algoritme zowel te hoog als te laag kunnen uitvallen, en we willen niet dat positieve en negatieve verschillen elkaar opheffen. Door de verschillen tussen de werkelijke en voorspelde verkoopprijzen te kwadrateren, worden ze allemaal positief en kunnen ze worden opgeteld.
'Door de verschillen tussen de werkelijke en voorspelde verkoopprijzen te kwadrateren, worden ze allemaal positief en kunnen ze worden opgeteld.'
De waarde van de gemiddelde kwadratenfout is afhankelijk van de eenheden waarin de doelvariabele is uitgedrukt. Ter illustratie, in dit voorbeeld zijn de verkoopprijzen voor alle woningen uitgedrukt in euro's, waardoor de gemiddelde kwadratenfout wordt weergegeven in termen van gekwadrateerde euro's. Als je de verkoopprijzen uitdrukt in eurocenten door ze te vermenigvuldigen met honderd, dan zullen de voorspelde verkoopprijzen ook in eurocenten zijn. In dat geval zal de gemiddelde kwadratenfout worden uitgedrukt in gekwadrateerde eurocenten en tienduizend keer groter zijn.
Deze afhankelijkheid maakt dat er geen algemene richtlijn bestaat die aangeeft wanneer deze maatstaf voldoende kwaliteit van het model aantoont. Hoewel de gemiddelde kwadratenfout dus niet eenvoudig te interpreteren is, noem ik deze maatstaf hier toch omdat het de standaardmanier is om een regressiemodel te optimaliseren en te beoordelen.
Gemiddelde voorspellingsfout
Een intuïtievere maatstaf voor de kwaliteit van het regressiemodel is echter de gemiddelde absolute voorspellingsfout (MAE, Mean Absolute Error). Deze waarde geeft de gemiddelde voorspellingsfout weer in de oorspronkelijke eenheden van de doelvariabele, in dit geval euro's. Een gemiddelde absolute voorspellingsfout van 55.953,056 betekent dat bij het voorspellen van de prijs van een willekeurige woning in de testset, de voorspelling gemiddeld € 55.953,06 afwijkt van de daadwerkelijke verkoopprijs.
Om inzicht te krijgen in de relatieve afwijkingen tussen de voorspelde verkoopprijzen en de werkelijke verkoopprijzen, kun je de absolute voorspellingsfouten uitdrukken als een percentage van de werkelijke verkoopprijzen en daarvan het gemiddelde nemen. Deze maatstaf, bekend als de gemiddelde absolute percentagefout (MAPE, Mean Absolute Percentage Error), is te vinden in de voorlaatste rij van de tabel en bedraagt 5,42 procent. Dit houdt in dat de voorspelde verkoopprijzen gemiddeld 5,42 procent verschillen van de werkelijke verkoopprijzen.
Als laatste kun je voor de evaluatie van de kwaliteit van het algoritme kijken naar de determinatiecoëfficiënt R2 (James et al., 2023, pp. 78–80), die ook bekend is van lineaire regressie. Deze is te vinden in de onderste regel van de tabel met kwaliteitsmaten. Hieruit blijkt dat het algoritme middels de bouwtechnische kenmerken 95,7 procent van de variantie in de verkoopprijs kan verklaren.
Je kunt het algoritme nog verder optimaliseren door de 'Algoritme-instellingen' aan te passen in de interface. Dit gaat echter te diep de materie in om ook in deze column te bespreken.
Toepassen
Als je tevreden bent met de prestatie van het algoritme, is de volgende stap om voorspellingen te maken voor de verkoopprijs van de honderd woningen in de portfolio van de vastgoedontwikkelaar. In JASP kun je dit doen door eerst het getrainde algoritme op te slaan. Dit doe je door de optie 'Getraind model opslaan' aan te vinken. De gegevens van de woningen in de portfolio van de vastgoedontwikkelaar kun je daarna inladen in een nieuwe sessie.
'Met de voorspelde verkoopprijzen kun je een diepgaande analyse uitvoeren.'
Vervolgens ga je naar de optie 'Voorspellen' in het Machine Learning-menu en laad je het opgeslagen model in. De bouwtechnische kenmerken van de woningen sleep je naar het daarvoor bedoelde veld. Daarna klik je onderaan de interface op 'Voorspellingen toevoegen aan gegevens' en vul je Voorspeld in als kolomnaam. Dit zorgt ervoor dat de voorspelde verkoopprijzen in een nieuwe kolom worden toegevoegd aan de gegevens.
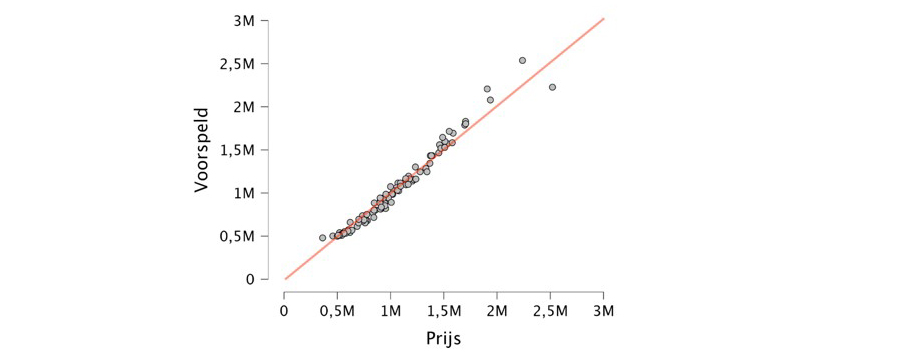
Met de voorspelde verkoopprijzen kun je een diepgaande analyse uitvoeren. Je kunt beginnen met een visuele inspectie op uitschieters door de voorspelde en de gerapporteerde verkoopprijzen in een spreidingsdiagram tegen elkaar af te zetten, zoals hieronder weergegeven6. De rode lijn duidt aan waar de voorspelde verkoopprijs overeenkomt met de gerapporteerde verkoopprijs.
Woningen waarbij de voorspelde verkoopprijs lager is dan de gerapporteerde verkoopprijs worden aangegeven door punten die onder de rode lijn liggen, terwijl woningen waarbij de voorspelde verkoopprijs hoger is dan de gerapporteerde verkoopprijs worden aangegeven door punten die boven de rode lijn liggen. In de figuur vallen enkele woningen op doordat de voorspelde verkoopprijs aanzienlijk verschilt van de gerapporteerde verkoopprijs.
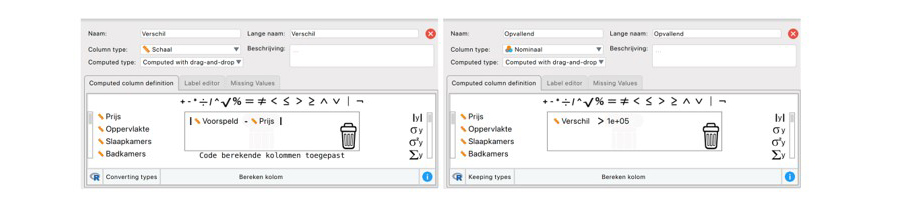
Om deze opvallende woningen te identificeren in de gegevens kun je een nieuwe kolom aanmaken in de gegevens die het absolute verschil tussen de voorspelde en de gerapporteerde verkoopprijzen aangeeft. Dit doe je door naar het '+'-icoon te gaan, dat zich rechts naast de laatste kolom in de gegevens bevindt, en hierop te klikken.
Vervolgens noem je deze kolom Verschil en geef je middels de drag-en-drop interface aan dat hierin de absolute waarde van de kolom Prijs minus de kolom Voorspeld moet komen te staan (zie linker afbeelding hieronder). Daarna kun je bijvoorbeeld een kolom aanmaken met de naam Opvallend waarin je aangeeft of het absolute verschil groter is dan een bepaald bedrag, bijvoorbeeld € 100.000 (zie rechter afbeelding hieronder).
Ten slotte kun je naar 'Beschrijvende statistiek' gaan om deze twee nieuwe kolommen te analyseren. Je kunt bijvoorbeeld het aantal woningen bepalen dat meer dan €100.000 afwijkt door een frequentietabel op te vragen van de variabele Opvallend (TRUE voor meer dan € 100.000 afwijking, FALSE voor minder dan €100.000 afwijking). Uit deze tabel, die hieronder is weergegeven, blijkt dat voor veertien van de honderd woningen de voorspelde verkoopprijs minimaal €100.000 afwijkt van de gerapporteerde verkoopprijs.

Acties
Op basis van deze resultaten kun je het verdere verloop van het fraudeonderzoek bepalen. Je zou bijvoorbeeld kunnen besluiten om de verkoopdocumenten van de veertien opvallende woningen integraal te controleren. Dit omvat het verifiëren van alle relevante documenten, zoals koopcontracten, taxatierapporten, en financiële transactieregisters.
Natuurlijk kun je deze workflow in JASP ook gebruiken om een regressiealgoritme te trainen voor andere auditdoeleinden. Als je deze technieken zelf toe wilt passen, dan kun je JASP gratis downloaden en installeren via www.jasp-stats.org.
Voetnoten
-
De originele dataset is te vinden op https://www.kaggle.com/datasets/yasserh/housing-prices-dataset.
-
De (licht) bewerkte versie van de originele dataset is te vinden op https://www.statisticalauditing.com/files/resources/data_housing_traintest.csv.
-
Deze gegevens zijn te vinden op https://www.statisticalauditing.com/files/resources/data_housing_prediction.csv.
-
Merk op dat er in totaal dus vier soorten datasets zijn: training (276), validatie (69), test (100) en toepassing (100).
-
De tweede en derde rij van de tabel tonen simpele transformaties van de gemiddelde kwadratenfout en worden daarom niet in de tekst besproken. De tweede rij toont de MSE (geschaald), wat de gemiddelde kwadratenfout is, geschaald zodat deze tussen 0 en 1 valt. De derde rij toont de vierkantswortel van de gemiddelde kwadratenfout (RMSE, Root Mean Squared Error).
-
Deze grafiek is gecreëerd door de 'Bayesiaanse correlatie' analyse te gebruiken, naar het gedeelte 'Grafieken van individuele paren' te navigeren en vervolgens de variabelen Prijs en Voorspeld in te voeren. De rode lijn is toegevoegd buiten JASP om.
Referenties
JASP Team. (2024). JASP (Versie 0.18.3)[Computer software]. https://jasp-stats.org
James, G., Witten, D., Hastie, T., Tibshirani, R., & Taylor, J. (2023). An Introduction to Statistical Learning with Applications in Python. Springer. https://hastie.su.domains/ISLP/ISLP_website.pdf.download.html
Gerelateerd

Voorraadcontroles: schatten van de werkelijke waarde met open-source software
Bij de controle van handels en productieondernemingen wordt vaak een fysieke voorraadcontrole uitgevoerd. Daarbij komen regelmatig afwijkingen aan het licht, bijvoorbeeld...

Auditen van de eerlijkheid van een algoritme, met behulp van statistiek
Eind 2024 trad de EU-wetgeving op kunstmatige intelligentie (AI) in werking. Deze wetgeving is opgesteld om het toenemende gebruik van AI in besluitvormings- en...

De Wet van Benford
De Wet van Benford kent toepassingen binnen de audit en is opgenomen in veel auditsoftwarepakketten. Een verkenning van mogelijkheden, beperkingen en toetsing met...

Symposium over statistiek in ESG
Hoe ver is de auditpraktijk met het toepassen van data-analyse op het gebied van ESG? De Stuurgroep Statistical Auditing van het Limperg Instituut gaat daarop in,...

Machine learning in de audit: stratificeren van bedrijfslocaties
In dit derde en laatste deel van een reeks columns over machine learning in de audit gaat het over clusteren. De auteurs laten zien hoe je met een open-source statistiekprogramma...