Voorraadcontroles: schatten van de werkelijke waarde met open-source software
Bij de controle van handels en productieondernemingen wordt vaak een fysieke voorraadcontrole uitgevoerd. Daarbij komen regelmatig afwijkingen aan het licht, bijvoorbeeld door diefstal in een elektronicazaak of door beschadiging van goederen in een houtzagerij. In dergelijke situaties komt de administratieve voorraad niet overeen met de feitelijke voorraad. Voor een accountant is het dan essentieel om de werkelijke waarde van de voorraad vast te stellen, zodat deze juist kan worden verwerkt in de financiële administratie.
Koen Derks
Een juiste waardering draagt bij aan een betrouwbare balans en winst‑ en verliesrekening en maakt het mogelijk potentiële risico's tijdig te signaleren. In deze bijdrage laat ik zien hoe je met het gratis, open‑source statistiekprogramma JASP de werkelijke waarde van een voorraad (of van elke andere financiële populatie) eenvoudig kunt schatten en de resultaten transparant kunt documenteren. Voor zover mij bekend biedt geen ander statistiekprogramma een automatische implementatie van de benodigde berekeningen voor deze methode, inclusief documentatie en interpretatie van de resultaten voor in het auditrapport. Alternatieven vergen ofwel handmatig rekenwerk, dat tijdrovend is, berekeningen in Excel, die gevoelig zijn voor fouten, of alleen resultaten, die je vervolgens zelf moet interpreteren. Het gebruik van JASP kan je daarom helpen om zowel tijd te besparen als de kans op onnauwkeurigheden te verkleinen.
Schatten van de werkelijke waarde
Wanneer je verwacht dat in een populatie veel fouten voorkomen, zoals bij voorraadcontroles vaak het geval is, dan is de kans reëel dat de fout de uitvoeringsmaterialiteit zal overschrijden. In dergelijke situaties is het noodzakelijk om de omvang van de fout te kunnen kwantificeren. Daarnaast is het, wanneer je zowel overstatements als understatements verwacht, wat eveneens typisch is bij voorraadcontroles, nodig om een postensteekproef toe te passen. Bij een geldsteekproef krijgen bepaalde producten in dat geval namelijk een te lage trekkingskans (zie het voorbeeld in een eerdere bijdrage van Paul van Batenburg op deze site). Onder deze omstandigheden kun je je beter richten op het bepalen van de werkelijke waarde van een voorraad met gebruik van een postensteekproef.
Om de werkelijke waarde van een voorraad te bepalen, kun je een statistische methode gebruiken, een proces dat bekend staat als schatten. Het voordeel hiervan is dat je slechts een deel van de voorraad fysiek hoeft te tellen. De methode levert namelijk een schattingsinterval op met een vooraf gekozen betrouwbaarheid, bijvoorbeeld 95 procent. Zo'n interval maakt de onzekerheid expliciet die ontstaat doordat je niet de totale voorraad hebt geteld. Hierdoor kun je efficiënter werken: je beperkt de telling tot een steekproef, terwijl je toch een onderbouwde en reproduceerbare schatting krijgt voor de werkelijke waarde van de totale voorraad.1
Voor het bepalen van zo'n schattings- of betrouwbaarheidsinterval bestaan meerdere methoden, waaronder de directe schatter, de verschilschatter, de quotiëntschatter en de regressieschatter (Touw & Hoogduin, 2012, hoofdstuk 8). De theoretische basis van deze vier methoden is uitgebreid besproken in een eerder artikel van Ferry Geertman en Hein Kloosterman en zal ik hier daarom alleen heel summier samenvatten. Lezers die hun theoretische kennis willen opfrissen, verwijs ik graag naar die bijdrage. In deze beperk ik mij tot de praktische toepassing van de regressieschatter.
De regressieschatter maakt gebruik van zowel de boekwaardes als de werkelijke waardes én van het lineaire verband tussen deze twee2. Daarmee verschilt de methode van de directe schatter, die uitsluitend de werkelijke waardes benut, van de verschilschatter, die zich alleen richt op de foutbedragen, en van de quotiëntschatter, die alleen uitgaat van de verhouding tussen boek- en werkelijke waardes. De regressieschatter is vooral geschikt in situaties waarin de totale fout bestaat uit twee componenten: een absolute fout, die onafhankelijk is van de boekwaarde van een post, én een relatieve fout, die afhankelijk is van die boekwaarde. Bij voorraadcontroles is het bestaan van deze beide componenten vaak een realistische aanname. Zo kan een medewerker van een elektronicawinkel bijvoorbeeld terughoudend zijn om meer dan € 500 aan producten te stelen, wat leidt tot een fout die onafhankelijk is van de boekwaarde van het product. Daarnaast kan door breuk structureel een percentage, bijvoorbeeld 1 procent, van een productcategorie verloren gaan, wat leidt tot een fout die afhankelijk is van de boekwaarde van het product.
Voorbeeld
Om de toepassing van de regressieschatter te illustreren, werk ik een concreet voorbeeld uit. Stel dat je bij een middelgrote supermarkt de voorraad controleert. De totale voorraad bestaat uit duizend producten, met een administratieve waarde van € 769.458. Omdat het onpraktisch is om de totale voorraad fysiek te tellen, heb je een steekproef genomen om de werkelijke waarde te schatten.
In dit voorbeeld spreek je van een fout als het aantal producten in het magazijn van de supermarkt niet overeenkomt met de administratieve registratie. Hierbij is het realistisch om zowel overstatements als understatements aan te treffen. Door diefstal of slordige registratie van derving zijn er vaak minder producten aanwezig dan in het systeem staat. Tegelijkertijd kunnen slecht vastgelegde retourstromen er ook toe leiden dat er juist méér producten op voorraad zijn dan geregistreerd staan. Omdat je zowel overstatements als understatements verwacht, heb je een postensteekproef gebruikt.
In dit voorbeeld heb je al een steekproef van 150 producten getrokken. Na de fysieke telling blijkt dat bij 32 producten het werkelijke aantal afwijkt van de administratieve registratie. Op basis van deze steekproef wil je vervolgens een schatting maken van de werkelijke waarde van de totale voorraad. Voor deze schatting hanteer je een betrouwbaarheid van 95 procent en een vereiste onnauwkeurigheid van € 11.000. Die tolerantie van € 11.000 is gekozen omdat zij ongeveer overeenkomt met 1,5 procent van de administratieve waarde van de totale voorraad.
Toepassen van de regressieschatter met JASP
Om de regressieschatter in JASP toe te passen, begin je met het downloaden en installeren van JASP via www.jasp-stats.org. Stel vervolgens via het menu linksboven (Preferences - Interface - Preferred language) de interface en resultaten in op Nederlands. Importeer daarna de steekproeflijst3 in JASP en activeer de Audit‑module door rechtsboven op het '+'-symbool te klikken en 'Audit' te selecteren. De module verschijnt daarna als extra tab in de bovenste menubalk.
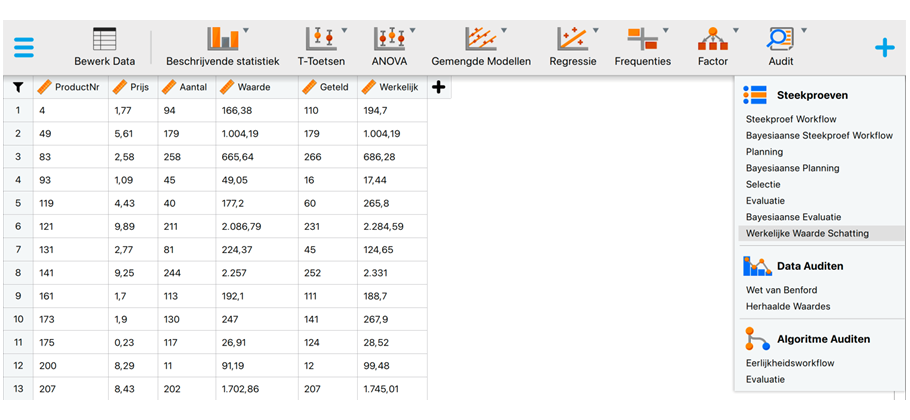
Open vervolgens binnen de Audit‑module de analyse 'Werkelijke Waarde Schatting'. Sleep de variabele Waarde naar het veld 'Boekwaarde' en de variabele Werkelijk naar het veld 'Auditwaarde'. Vul in de sectie 'Populatie' het 'Aantal posten' in als 1.000 en het 'Aantal eenheden' als 769.458. Selecteer daarna in de sectie 'Rapport' de tabel 'Vereiste steekproefomvang' en vul bij 'Onnauwkeurigheid' de waarde 11.000 in. Hiermee berekent JASP automatisch de vereiste steekproefomvang voor een onnauwkeurigheid van € 11.000, voor het geval de huidige steekproef niet aan deze nauwkeurigheidsgrens voldoet.
Resultaten
Nadat je de bovenstaande instellingen hebt ingevoerd, berekent JASP automatisch de resultaten en verschijnt de onderstaande tabel. Daaruit blijkt dat de puntschatting van de werkelijke waarde van de totale voorraad € 757.392,59 bedraagt. De onnauwkeurigheid van deze schatting (het verschil tussen de puntschatting en de boven- of ondergrens van het interval) is € 11.830,98. Dit resulteert in een 95 procent betrouwbaarheidsinterval, die loopt van € 745.561,61 tot € 769.223,584. Omdat de administratieve waarde van de totale voorraad (€769.458) buiten deze interval valt, kun je op basis van de steekproef met 95 procent zekerheid concluderen dat deze administratieve waarde geen getrouw beeld geeft van de werkelijke waarde van de totale voorraad.

In dit voorbeeld is de verkregen onnauwkeurigheid (€11.830,98) groter dan de vooraf vereiste onnauwkeurigheid van €11.000 en ligt de bovengrens bovendien dicht bij de administratieve waarde. Om het schattingsinterval te verkleinen, zodat het wél voldoet aan de gestelde onnauwkeurigheid, kun je de steekproef uitbreiden. Een grotere steekproef verkleint de onzekerheid in de schatting en zorgt er ook voor dat je met meer zekerheid kunt vaststellen dat de administratieve waarde geen getrouw beeld geeft van de werkelijke waarde.
De tabel Vereiste Steekproefomvang in de JASP‑output toont hoeveel waarnemingen nodig zijn om de onnauwkeurigheid terug te brengen tot € 11.000. In dit geval is een totale steekproefomvang van 170 producten vereist. Aangezien je al 150 producten hebt geteld, betekent dit dat je een aanvullende steekproef van 20 producten nodig hebt5.

Tot slot kun je via de knop 'Download Rapport' de volledige analyse inclusief bijbehorende uitleg exporteren naar een auditrapport. Zo heb je de analyse meteen netjes gedocumenteerd.
Conclusie
Zoals je hebt kunnen lezen in deze bijdrage, kun je met de regressieschatter een nauwkeurige en efficiënte schatting maken van de werkelijke waarde van een voorraad op basis van een postensteekproef, inclusief betrouwbaarheid en tolerantie. Met behulp van de gratis open‑source software JASP kun je deze schatting bovendien eenvoudig berekenen én transparant documenteren.
Noten
-
De uitkomst van de steekproef kan ook worden gebruikt om te toetsen op een materiële afwijking.
-
Om de regressieschatter betrouwbaar te kunnen toepassen, moeten de gegevens voldoen aan de klassieke aannames van regressieanalyse. Dit houdt onder meer in dat de relatie tussen boekwaarde en werkelijke waarde lineair is, dat de residuen normaal verdeeld zijn, dat de variantie van de residuen constant blijft (homoscedasticiteit), dat er geen autocorrelatie aanwezig is en dat de gegevens geen uitbijters of andere punten bevatten die onevenredig veel invloed uitoefenen op de geschatte relatie. Zie Touw en Hoogduin (2012, hoofdstuk 9) voor meer details.
-
De steekproeflijst is hier te vinden.
-
Volgens Touw en Hoogduin (2012, Hoofdstuk 8) is de formule voor de regressieschatter met eindigheidscorrectie N × w̅ + b1 × (B – N × b̅) ± tα/2[n – 1] × sw × √(1 – rbw2) × (N / √n) × √((N – n) / (N – 1)). Hierin is N het aantal posten in de populatie, B het aantal euro’s in de populatie, n het aantal posten in de steekproef, b̅ en w̅ de gemiddelde boek- respectievelijk werkelijke waarde van deze posten, sw de standaardafwijking van de werkelijke waardes, en rbw de correlatie tussen de boekwaarde en de werkelijke waarde van de posten in de steekproef. Invullen geeft 1.000 × 815,398 + 0,99813 × (769.458 – 1.000 × 827,572) ± 1,976 × 671,963 × √(1 – 0,992982) × (1.000 / √150) × √((1.000 – 150) / (1.000 – 1)) = [€ 745.564,10; € 769.221,30]. Deze uitkomsten verschillen een klein beetje van de exacte uitkomsten in JASP, omdat ik hier tussentijds heb afgerond.
-
Merk op dat er geen garantie is dat na het controleren van deze twintig extra producten de vereiste onnauwkeurigheid wordt behaald. Dit komt doordat de samenhang tussen de boekwaarde en werkelijke waarde van deze producten kan afwijken van wat er tot nu toe in de steekproef is gezien. Als de werkelijke waardes in de aanvullende steekproef minder sterk samenhangen met de boekwaardes dan in de initiële steekproef, wordt de onnauwkeurigheid niet behaald. Omgekeerd, als de samenhang sterker is, wordt de onnauwkeurigheid wel behaald.
Referenties
-
JASP Team. (2025). JASP (Versie 0.95.4) [Computer software].
-
Touw, P. & Hoogduin, L. (2012). Statistiek voor Audit en Controlling. Boom, Amsterdam.
Gerelateerd

Auditen van de eerlijkheid van een algoritme, met behulp van statistiek
Eind 2024 trad de EU-wetgeving op kunstmatige intelligentie (AI) in werking. Deze wetgeving is opgesteld om het toenemende gebruik van AI in besluitvormings- en...

De Wet van Benford
De Wet van Benford kent toepassingen binnen de audit en is opgenomen in veel auditsoftwarepakketten. Een verkenning van mogelijkheden, beperkingen en toetsing met...

Symposium over statistiek in ESG
Hoe ver is de auditpraktijk met het toepassen van data-analyse op het gebied van ESG? De Stuurgroep Statistical Auditing van het Limperg Instituut gaat daarop in,...

Machine learning in de audit: stratificeren van bedrijfslocaties
In dit derde en laatste deel van een reeks columns over machine learning in de audit gaat het over clusteren. De auteurs laten zien hoe je met een open-source statistiekprogramma...

Machine learning in de audit: uitschieters bij vastgoedwaardering
Regressie is een vorm van machine learning met als doel het voorspellen van cijfers op basis van een aantal kenmerken. Met open-sourcesoftware kun je zonder programmeerkennis...